Movie Recommender System Using LLMs
Overview
Movie nights are great, but finding the perfect film can be a struggle, all of us gather up and waste so much time trying to decide what to watch. Current recommenders often miss the mark, suggesting generic options or overlooking the present mood.
This project tackles that challenge by creating a next-generation movie recommendation system which takes in an input prompt and suggests a list of movies (ranked) based on users’ taste profile, current mood, preferred genre and community reviews.
Imagine describing your ideal movie night - a thrilling action flick, a suspenseful detective film, or a feel-good romcom and getting the perfect recommendations that are relevant to your mood while having qualities that you generally like. Also utilizing feedback on the users choices refines the system, ensuring future suggestions hit the bullseye.
How it works?
Our movie dataset, the TMDB 5000 Movie Dataset, contains metadata of approximately 5000 movies from TMDb, a subset of the 1 million movies available in the large dataset. The user dataset contains 100 ratings from 700 users, a subset of the ratings available in the Full Movie Lens dataset. Both datasets are sourced from Kaggle.
Data Preprocessing:
Movie data: We merged two datasets (movie and credit data) based on movie IDs to integrate movie information, including directors, top three casts, genres, keywords, overview, and tagline.
User data: We retrieved user IDs, movie IDs, and ratings.
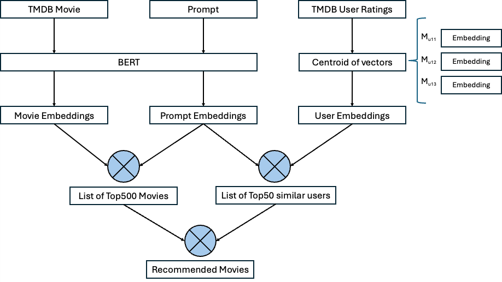
We started by retrieving movie data from TMDB and processed it through BERT to obtain movie embeddings. The prompt was also passed through BERT, yielding prompt embeddings. We computed movie embeddings for each user’s rated movies and calculated the centroid of these vectors to represent user embeddings.
Utilizing movie embeddings and prompt embeddings, we computed the dot product to generate a list of the top 500 movies. Similarly, by employing prompt embeddings and user embeddings, we identified a list of the top 50 similar users.
With these two lists, we then compute the dot product between the top 500 movies and the top 50 similar users to derive the recommended movies.
Results

Future Work
Instead of just using the dot product to compute the similarity score and finally the recommendations, I would like to use a deep learning model to do that for me.
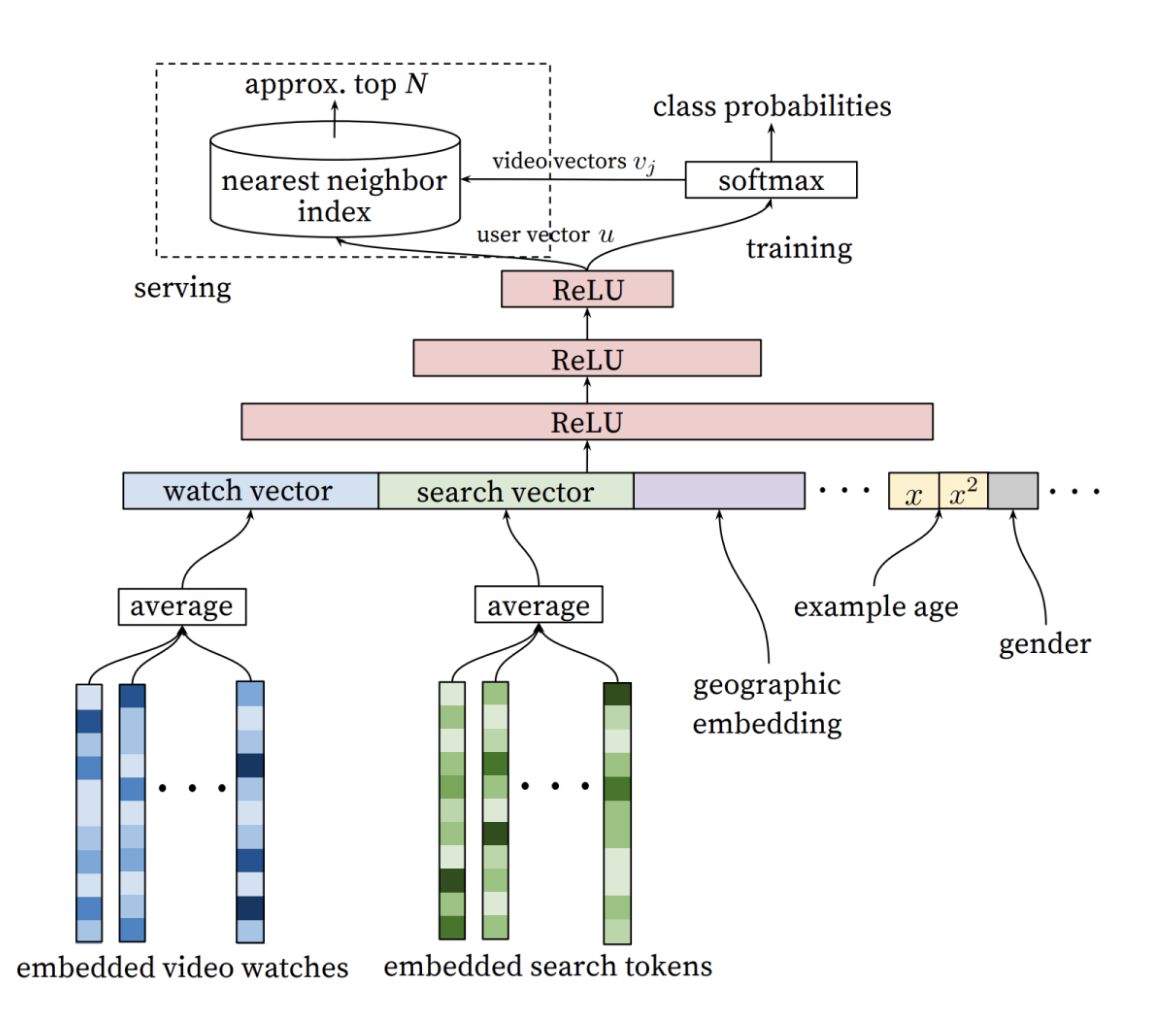
First I will append the user embeddings and movie embeddings and then use a manually scored dataset to train a 2-3 layer perceptron network to generate a similarity score for each movie in my list. I believe this will produce more robust and relevant results.